Azure OpenAI Intelligence Layer
This layer extends the Kafka → Delta Lake → MLflow pipeline with Azure OpenAI-powered anomaly explanations, MLflow AI evaluation, retrieval-augmented investigation, and a human review workflow.
AI Intelligence Flow
After anomalous events are written to gold_anomaly_predictions, the platform enriches them with Azure OpenAI,
evaluates structured output quality, retrieves operational context, and routes AI-assisted findings into human review.
AI Intelligence & Decision Support Workflow
This diagram shows the AI intelligence layer, including Azure OpenAI enrichment, retrieval-augmented generation (RAG), human review workflows, business impact analysis, and operational decision support.
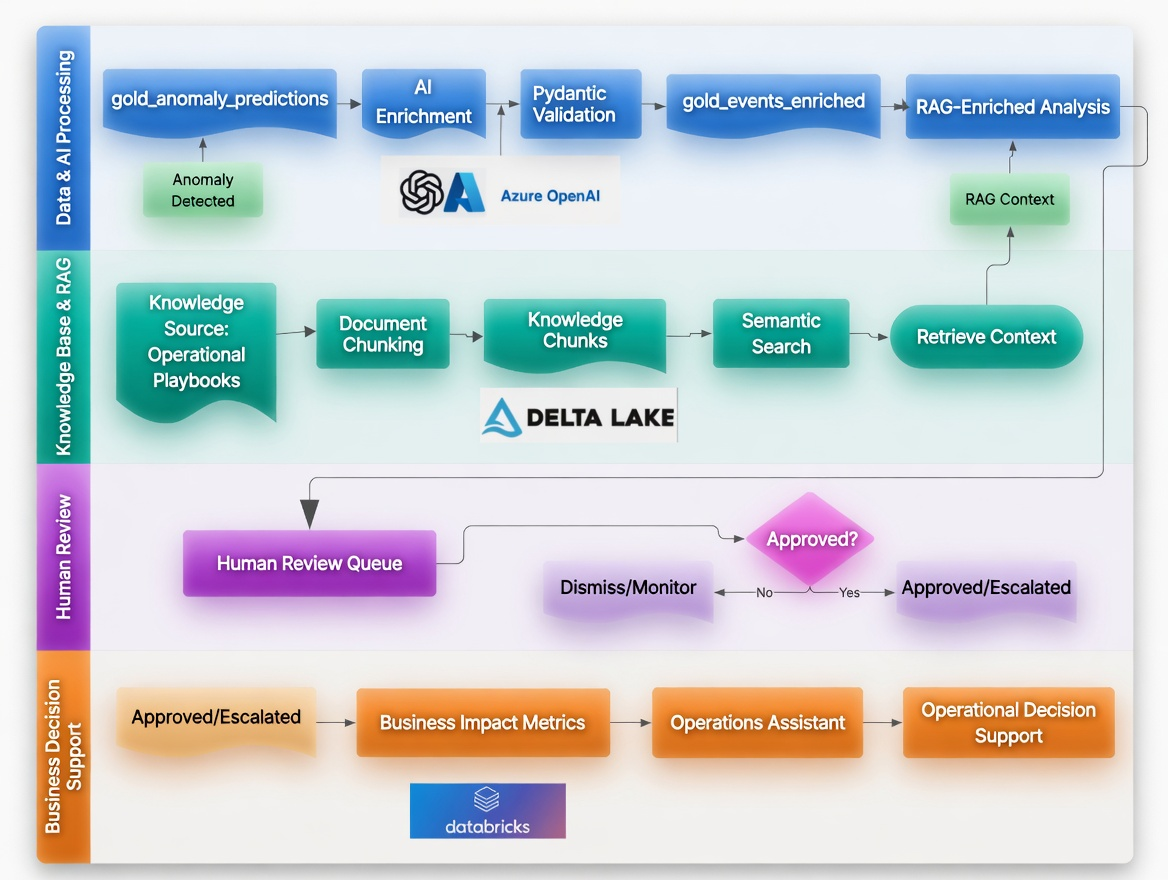
AI-enriched anomaly findings are grounded with retrieved operational context, routed through human review, translated into business impact metrics, and surfaced through natural language operational decision support.
Azure OpenAI Deployment
The GPT-4.1-mini model is deployed through Azure AI Foundry and used as the language model behind the anomaly enrichment step.
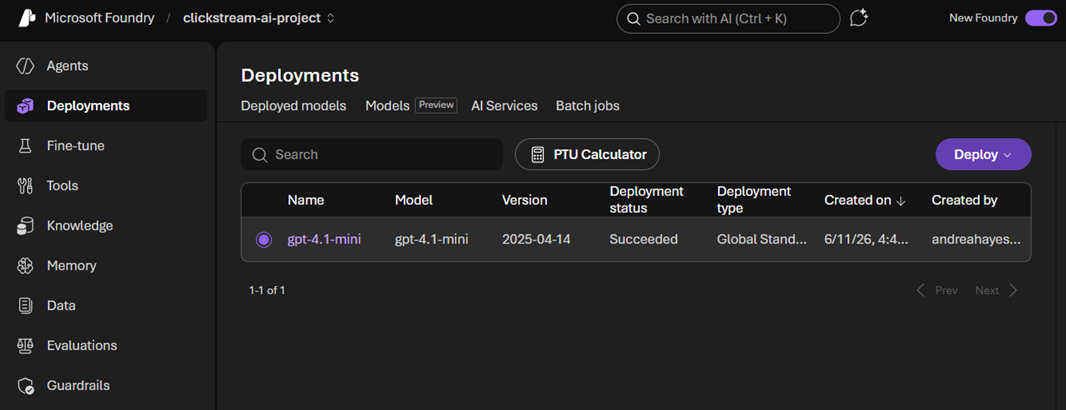
Azure OpenAI deployment showing the GPT-4.1-mini model used for structured anomaly explanations.
Databricks to Azure OpenAI Integration
The enrichment notebook runs in Databricks and sends inference requests to Azure OpenAI. This confirms that the Databricks analytics environment can call the AI model directly as part of the downstream processing workflow.
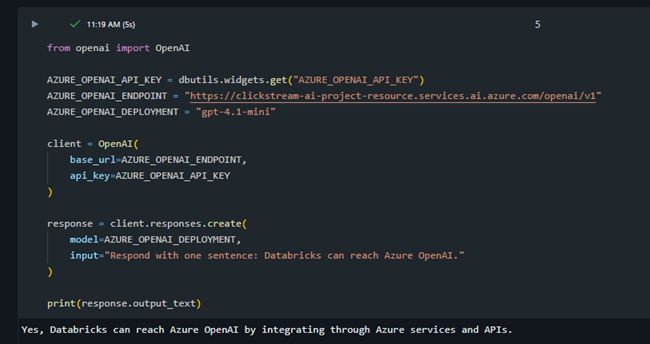
Databricks successfully connects to Azure OpenAI and receives a model response.
Structured Enrichment Output
The AI output is validated with Pydantic and written to the gold_events_enriched Delta table.
This creates a structured intelligence layer on top of the existing Gold anomaly predictions.

AI-generated summaries and inferred user intent persisted to the Gold enrichment table.
AI Risk Assessment
The enrichment layer generates risk levels and confidence scores so downstream analysts can prioritize which anomalies require review.
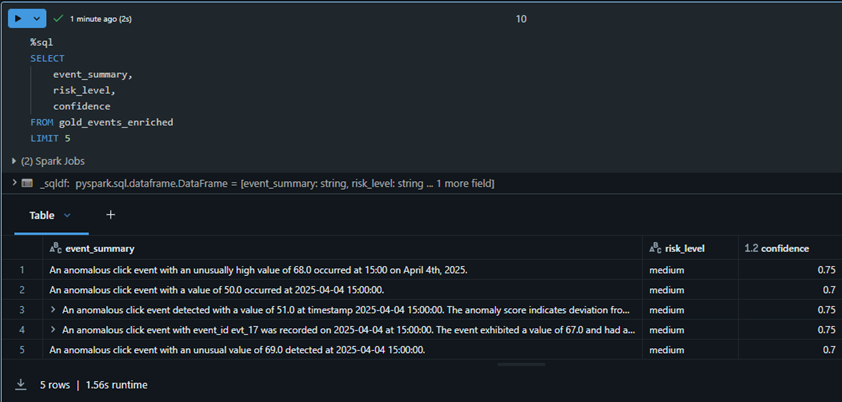
Structured risk levels and confidence scores produced by the Azure OpenAI enrichment step.
Structured Output Validation
The notebook validates model responses before writing to Delta. In the initial sample enrichment run, all generated outputs passed structured validation.
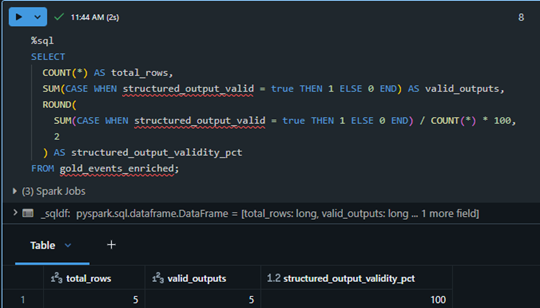
Validation query showing 100% structured output validity across the initial enrichment sample.
AI Evaluation and Prompt Tracking
Building AI features is only part of the challenge. Production systems also need visibility into response quality, confidence levels, prompt versions, and model behavior over time.
To support observability and future prompt experimentation, the project includes a dedicated AI evaluation workflow that validates structured outputs and records enrichment quality metrics to both Delta Lake and MLflow.
↓
Structured Output Validation
↓
MLflow Experiment Tracking
↓
ai_enrichment_eval_metrics
Delta-Based Evaluation History
Evaluation results are written to a dedicated Delta table, creating a persistent audit trail of AI enrichment quality across runs. Metrics include structured output validity, confidence scores, model version, prompt version, and runtime metadata.
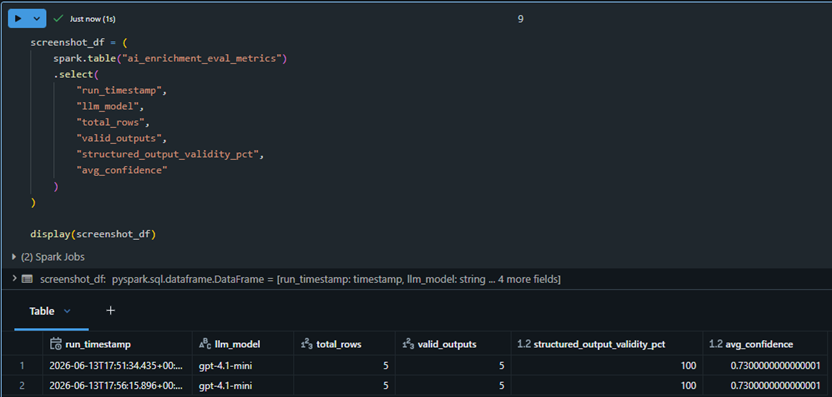
AI enrichment evaluation metrics persisted to Delta Lake for historical tracking and reporting.
MLflow Experiment Tracking
MLflow is used to track AI evaluation runs, allowing prompt versions, model versions, confidence metrics, and validation rates to be compared over time.
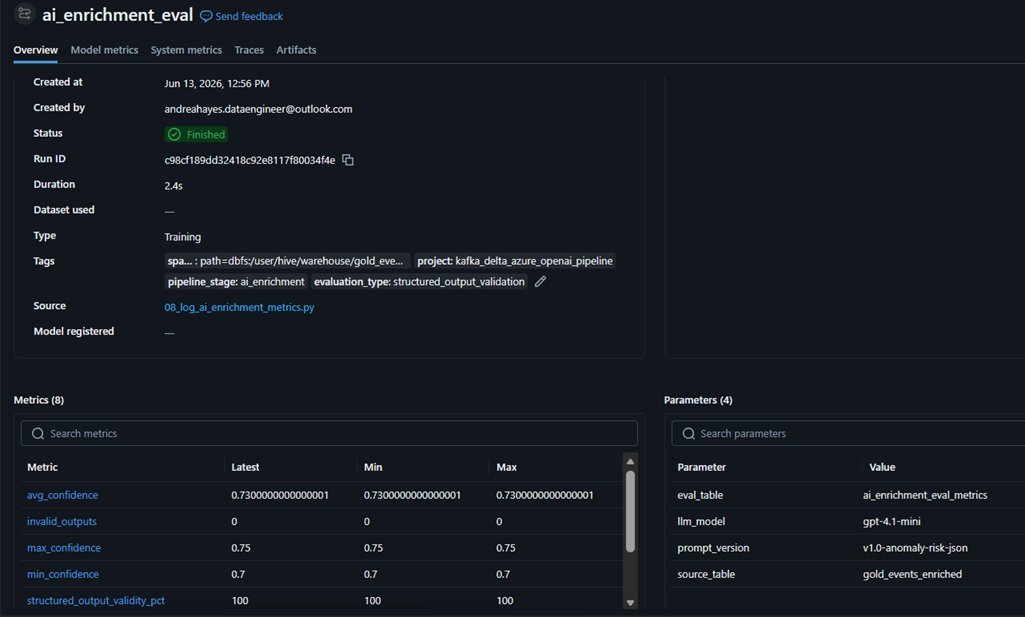
MLflow experiment tracking for AI enrichment quality, confidence metrics, prompt versions, and evaluation metadata.
Retrieval-Augmented Generation Investigation
The project now includes a RAG investigation layer that gives Azure OpenAI access to operational knowledge, including historical incidents and response playbooks. This allows the model to generate recommendations grounded in retrieved context rather than relying only on the raw anomaly row.
↓
knowledge_chunks
↓
Dynamic Retrieval
↓
Azure OpenAI GPT-4.1-mini
↓
gold_events_enriched_rag
Knowledge Base Chunks
Incident reports and operational playbooks are chunked and stored in the knowledge_chunks Delta table.
Retrieved chunks provide context such as payment outages, CDN latency incidents, checkout abandonment guidance,
and fraud response steps.
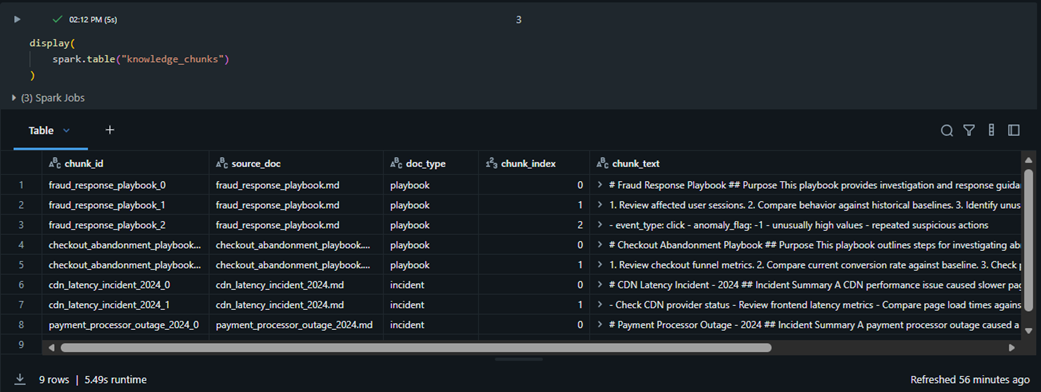
Operational incident reports and playbooks chunked into Delta Lake for RAG-based retrieval.
RAG-Enriched Output
The RAG workflow extends the original AI enrichment output with related incidents, recommended actions, and source document attribution.
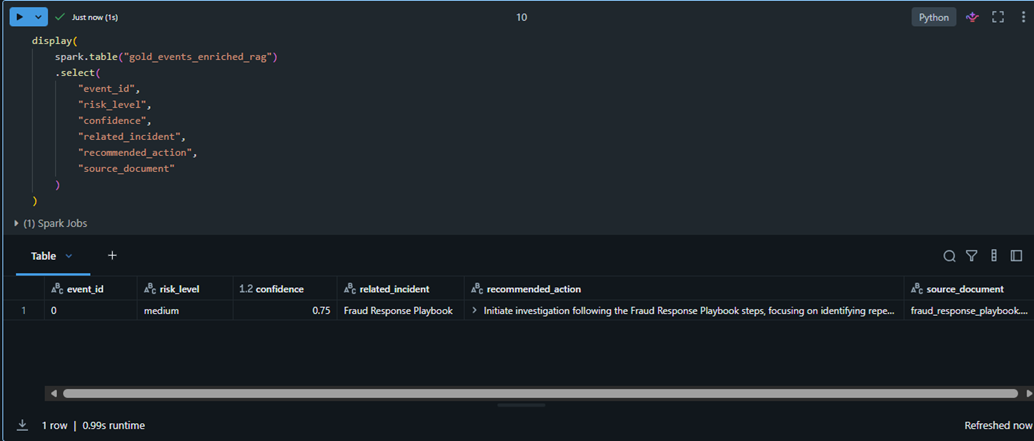
RAG-enriched anomaly output with incident-aware recommendations, risk context, and source attribution.
Human Review Queue
RAG-enriched anomalies are routed into a human-in-the-loop review workflow. This creates an auditable path from AI-generated recommendation to analyst decision.
↓
human_review_queue
↓
approved / escalated / dismissed
The review queue tracks review status, priority, analyst notes, reviewer identity, and timestamps. This simulates how production AI systems keep humans in control of operational decisions.
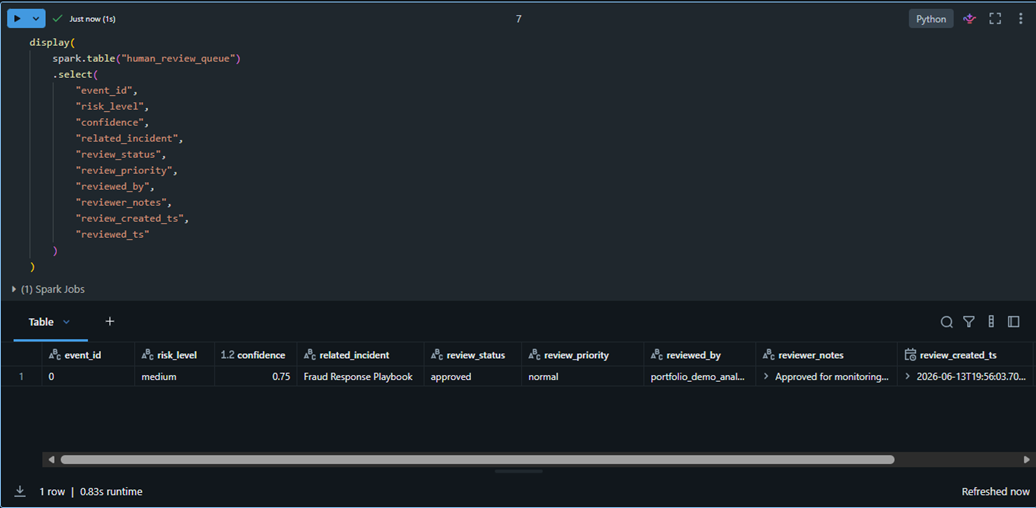
RAG-enriched anomalies routed into a human review queue for approval, escalation, and auditability.
Business Impact Simulation
The platform translates AI and RAG-enriched anomaly findings into business-oriented metrics, including estimated revenue at risk, affected session estimates, priority scores, and recommended escalation actions.
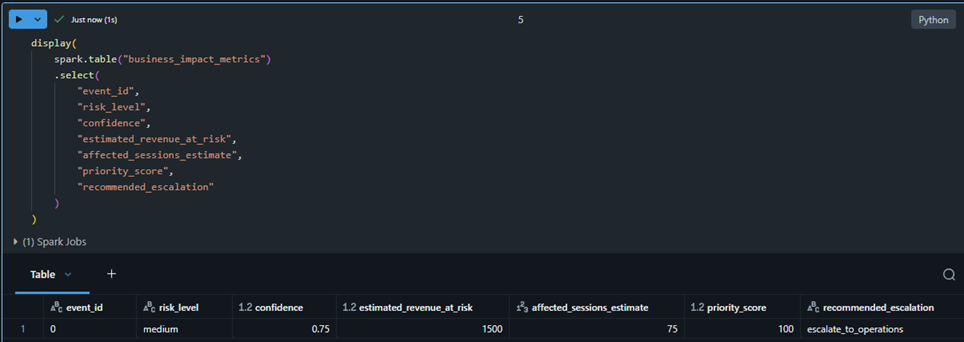
AI and RAG-enriched anomaly findings translated into estimated revenue at risk, affected sessions, priority scores, and escalation guidance.
Semantic Search
The knowledge base is vectorized using TF-IDF embeddings and ranked with cosine similarity, allowing relevant incident reports and playbooks to be retrieved from natural language queries.
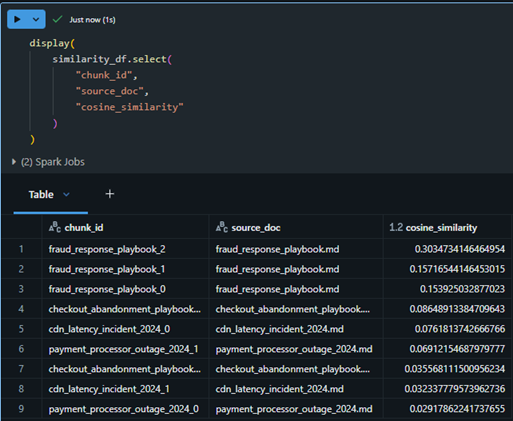
Knowledge base documents ranked by cosine similarity to retrieve relevant incidents and operational playbooks.
Why This Layer Matters
The original pipeline identified anomalous events using MLflow-tracked Isolation Forest scoring. The Azure OpenAI intelligence layer turns those model outputs into operational intelligence by generating summaries, inferred user intent, risk explanations, confidence scores, evaluation metadata, retrieved incident context, recommended actions, source attribution, and human review records.
- Before: anomaly scores and flags for downstream analysis
- After: structured explanations, RAG-based incident context, AI recommendations, and human review workflow
- Portfolio value: demonstrates Databricks, MLflow, Azure OpenAI, structured outputs, RAG, and human-in-the-loop AI operations in one system